Immobilier – Les Plus Beaux Logis de Paris (Openclassroom)
Analyser l’évolution des prix de l’immobilier avec Python
Fictif
|
11/04/2025 > 07/05/2025








Contexte
En tant que Business Intelligence Analyst chez ESN Data (fictif), j’ai été sollicité par Jade (la directrice) pour accompagner “Les Plus Beaux Logis de Paris” dans deux missions successives :
- Analyse historique : étudier l’évolution des prix de l’immobilier parisien (2017–2021) afin d’identifier les dynamiques de marché et les corrélations clés.
- Modélisation prédictive et clustering :
- Construire une régression linéaire pour prédire la valorisation future du portefeuille d’actifs de l’entreprise.
- Mettre en place un algorithme de clustering K‑Means pour classifier automatiquement les biens (appartements vs locaux commerciaux) et répondre au besoin exprimé par Louise (directrice « Les Plus Beaux Logis de Paris »).
Datasets
- df_histo_immo: historique des ventes immobilières à Paris entre 2017 et 2021 (transactions = 26196 , champs : date de mutation, valeur foncière, adresse numero, adresse voie, code postale, nom commune, code type local, type de bien, surface).
- df_actifs: portefeuille d’actifs de l’entreprise pour 2022, deux versions :
- Portefeuille 1 : 275 biens (154 particuliers, 121 corporate)
- Portefeuille 2: 469 biens (310 particuliers, 159 corporate) .
- Échantillon clustering: données des biens transmises par l’équipe de Louise pour valider le K‑Means.
Workflow
- Environnement : Jupyter Notebook (Python 3) bibliothèques pandas, numpy, matplotlib, seaborn, plotly, statsmodel, scikit‑learn.
- EDA:
- Vérification des types, comptage total et par type de bien.
- Calcul de l’intervalle temporel des données.
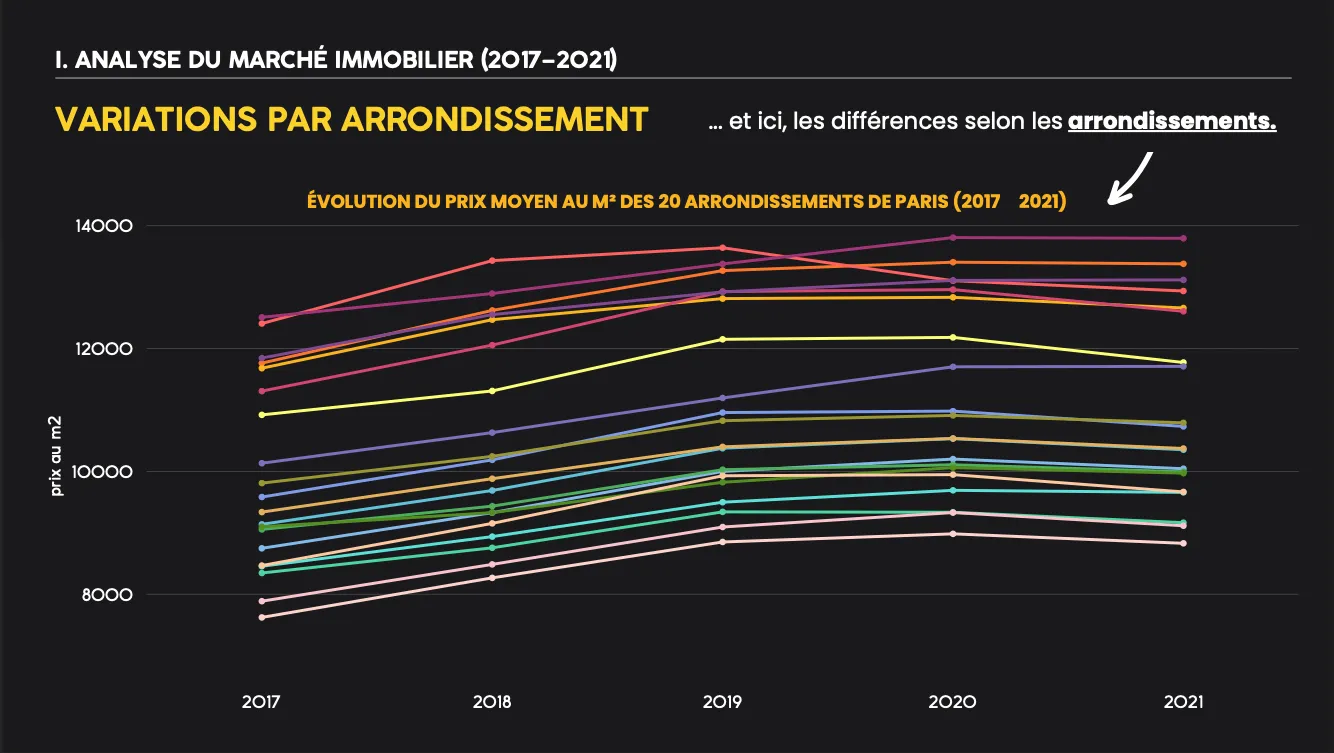
- Évolution du prix moyen €/m² global et par arrondissement (2017→2021).
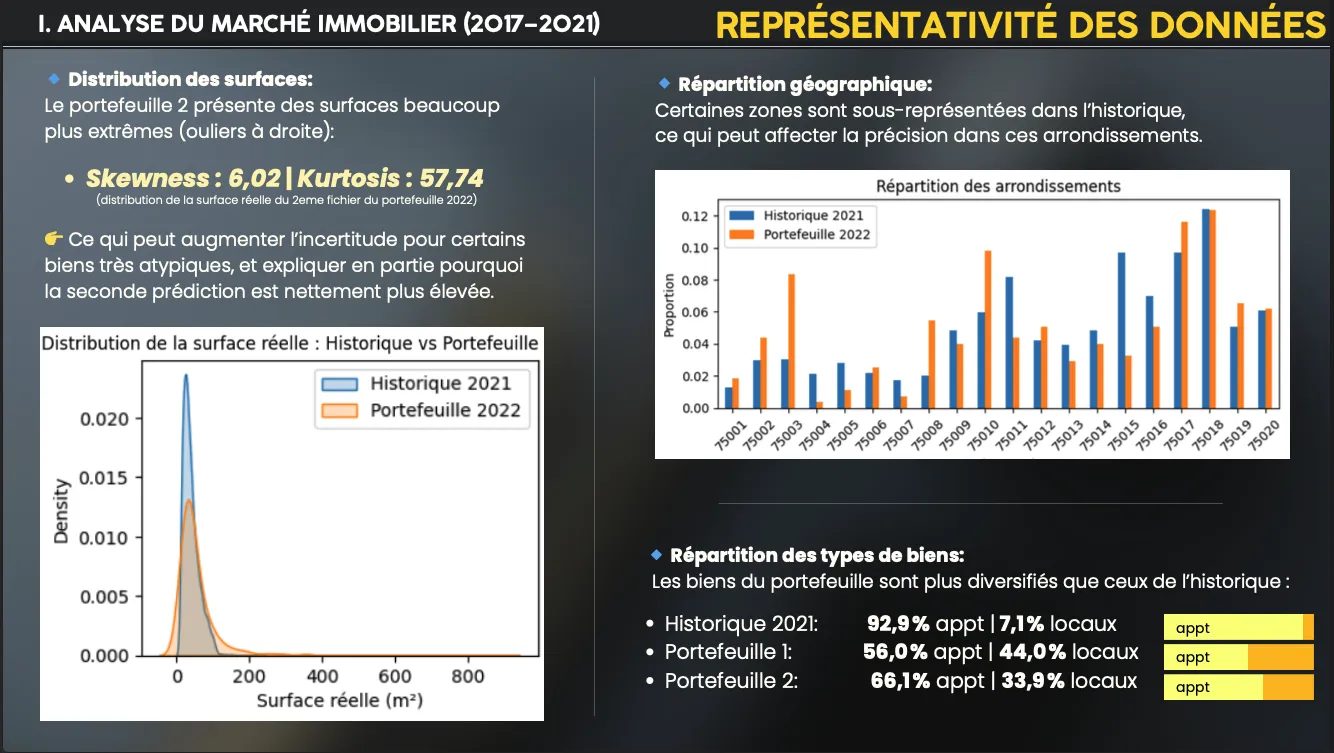
- Analyse de représentativité (répartition appartements vs locaux).
- Tests de corrélation de Pearson : prix €/m² vs date, prix €/m² vs surface.
- Comparaison des prix €/m² entre appartements et locaux.
- Régression linéaire :
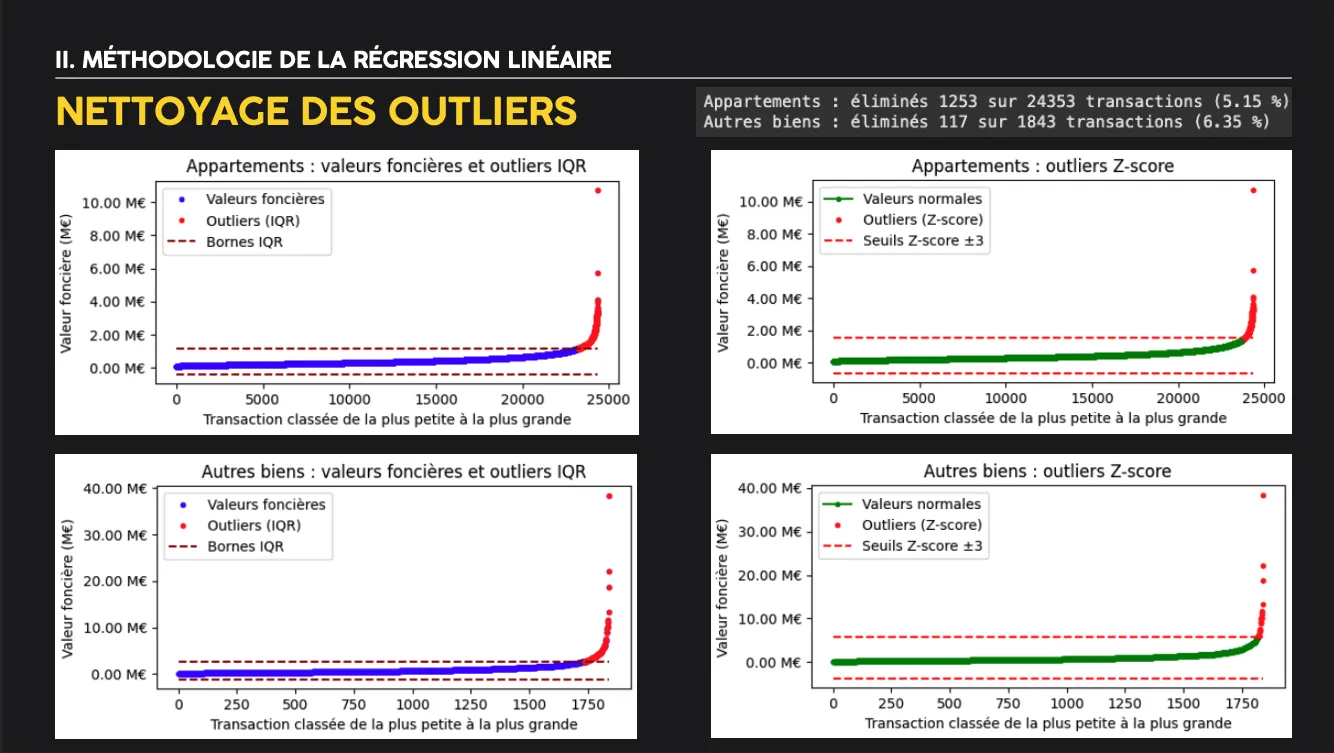
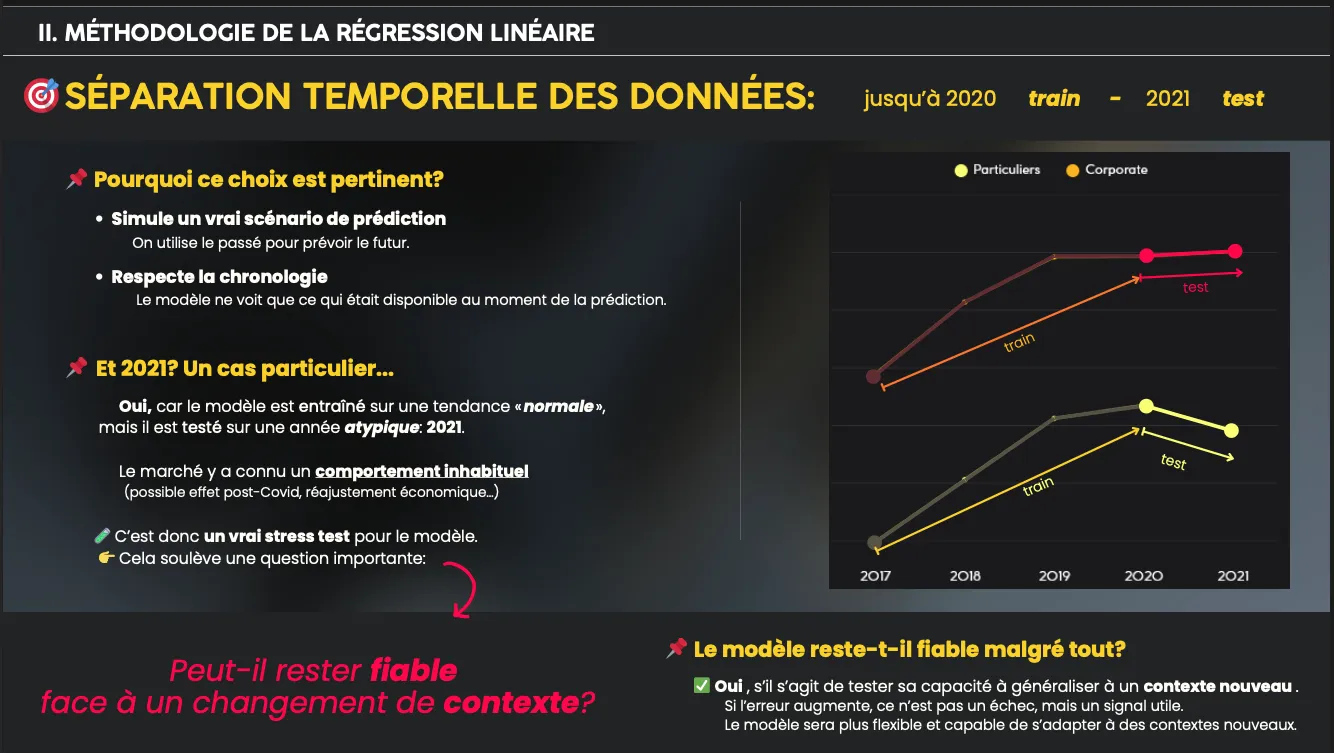
- Pré‑traitement : transformation logarithmique de la variable cible, one‑hot encoding des codes postaux, séparation temporelle train/test (train : ≤ 2020, test : 2021).
- Entraînement d’un modèle LinearRegression et évaluation par MAE en pourcentage.
- Validation : cible < 10 % d’erreur moyenne.
- K-Means clustering:
- Préparation : calcul du prix €/m², gestion des valeurs manquantes, sélection de la variable.
- Application de K‑Means (k=2), interprétation des centres, association aux catégories (appartement vs local).
- Évaluation : f1‑score, accuracy, matrice de confusion.
Insights
- Tendances de marché: la tendance avant covid était fortement croissante, après il y a eu un ralentissement. Chaque arrondissement se différencie des autres pour le prix, mais il mantient plus au moins la même tendance.
- Représentativité :
- Historique 2021 : 92,9 % appartements vs 7,1 % locaux
- Portefeuille 1 : 56,0 % appartements vs 44,0 % locaux
- Portefeuille 2 : 66,1 % appartements vs 33,9 % locaux
- Prédictions:
- Valorisation portefeuille 1 : 67,5 M€ (particuliers) | 111,9 M€ (corporate)
- Valorisation portefeuille 2 : 788,5 M€ (particuliers) | 52 454,8 M€ (corporate) .
- Erreur moyen pondérée: 1,08% train, 1,11% test
- Clustering:
- f1‑score = 1,00 ; accuracy = 100 %
- Classification sans erreur (matrice de confusion parfaite).
Business Impact
- Les directeurs disposent désormais d’une analyse historique solide pour comprendre les dynamiques de prix par arrondissement.
- Le modèle de régression permet d’anticiper la valorisation future du portefeuille avec une erreur maîtrisée (< 1,5%), facilitant les décisions d’investissement.
- Le clustering automatisé remplace l’enquête manuelle, économise du temps et garantit une classification fiable des biens.