Santé – European Cardiovascular Health Consortium (Personnel)
Prédire les maladies cardiaques grâce au Machine Learning
Fictif
|
01/10/2025 > 19/11/2025





Contexte
J'ai été mandaté par le Consortium européen pour la santé cardiovasculaire (ECHC) (fictif), un consortium à but non lucratif regroupant des centres de recherche cardiovasculaire, pour développer un système d'apprentissage automatique destiné au dépistage préventif des maladies cardiaques. Le projet était supervisé par le Dr Elena Rossi (responsable de la cardiologie préventive).
Mon rôle était de :
- Construire des modèles prédictifs pour évaluer le risque de maladie cardiovasculaire à partir de données cliniques
- Optimiser les performances du modèle tout en résolvant les problèmes d'overfitting
- Créer un tableau de bord Power BI interactif permettant aux cliniciens d'explorer des scénarios "what-if".
- Traduire les prédictions complexes du ML en catégories de risque exploitables (faible/modéré/élevé)
Datasets
Source:
Données sur les maladies cardiaques de l'UCI
Créateurs :
Institut hongrois de cardiologie (Budapest), Hôpital universitaire (Zurich), Hôpital universitaire (Bâle), Centre médical V.A. (Long Beach & Cleveland Clinic Foundation)
Dataset principal :
- 303 patients provenant de 4 hôpitaux internationaux
- 13 variables cliniques : âge, sexe, type de douleur thoracique (cp), tension artérielle au repos (trestbps), cholestérol (chol), glycémie à jeun (fbs), ECG au repos (restecg), fréquence cardiaque maximale (thalach), angine d'effort (exang), dépression du segment ST (oldpeak), pente du segment ST (slope), vaisseaux colorés (ca), thalassémie (thal)
- Variable cible : présence (1) ou absence (0) d'une maladie cardiaque
Qualité des données : Aucune valeur manquante
Défi : l'ensemble de données original comportait 5 classes déséquilibrées (0, 1, 2, 3, 4). Il a été transformé en classification binaire (santé vs maladie) afin d'obtenir des classes équilibrées : 160 personnes en bonne santé (54 %) vs 137 personnes malades (46 %).
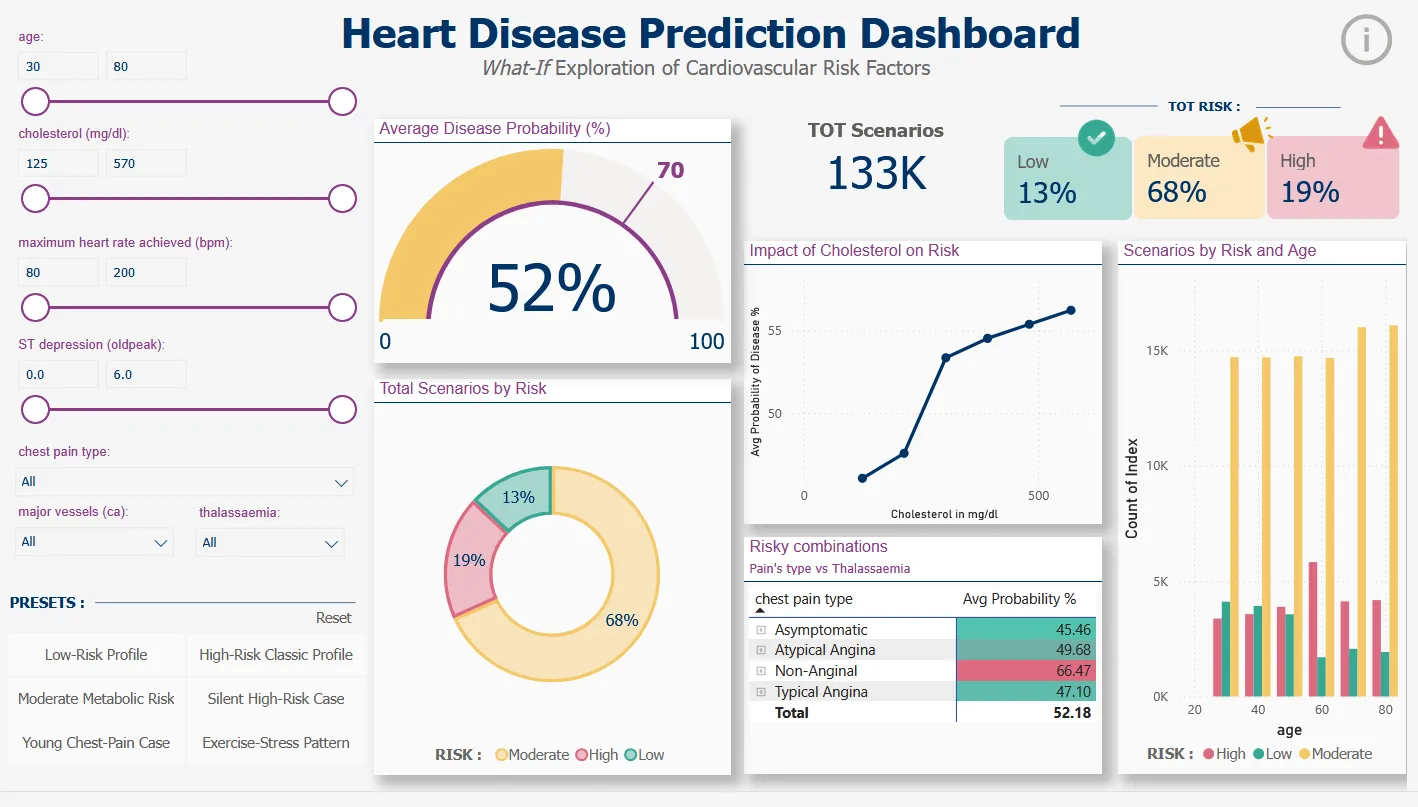
Ensemble de données du tableau de bord : 133 056 scénarios simulés générés par des combinaisons systématiques de paramètres cliniques pour l'analyse "what-if".
Workflow
Environnement : Jupyter Notebook (Python 3) using scikit-learn, pandas, numpy, matplotlib, seaborn, joblib
1. Préparation des données :
Train-test split : 80 % de training (237 patients) / 20 % de test (60 patients) avec stratification
Éviter le data snooping : test set verrouillé jusqu'à l'évaluation finale
Validation croisée 5-Fold pour le réglage des hyperparamètres fait uniquement sur le training set.
Pipeline de pré-traitement :
Variables numériques : imputation médiane + StandardScaler (μ=0, σ=1)
Variables catégorielles : One-Hot Encoding
2. Développement du modèle :
Modèle 1 – Random Forest :
GridSearchCV initial avec overfitting détecté (écart AUC : 5,1 %)
Stratégie de régularisation appliquée :
- Profondeur d'arbre limitée (max_depth : 10)
- Augmentation du nombre minimum d'échantillons par fractionnement (min_samples_split : 5)
- Augmentation du nombre minimum d'échantillons par feuille (min_samples_leaf : 4)
- Randomisation des caractéristiques (max_features: ‘sqrt’)
Résultat après optimisation : précision de 85 %, AUC de 0,946, réduction de l'écart de overfitting à 3,5 %.
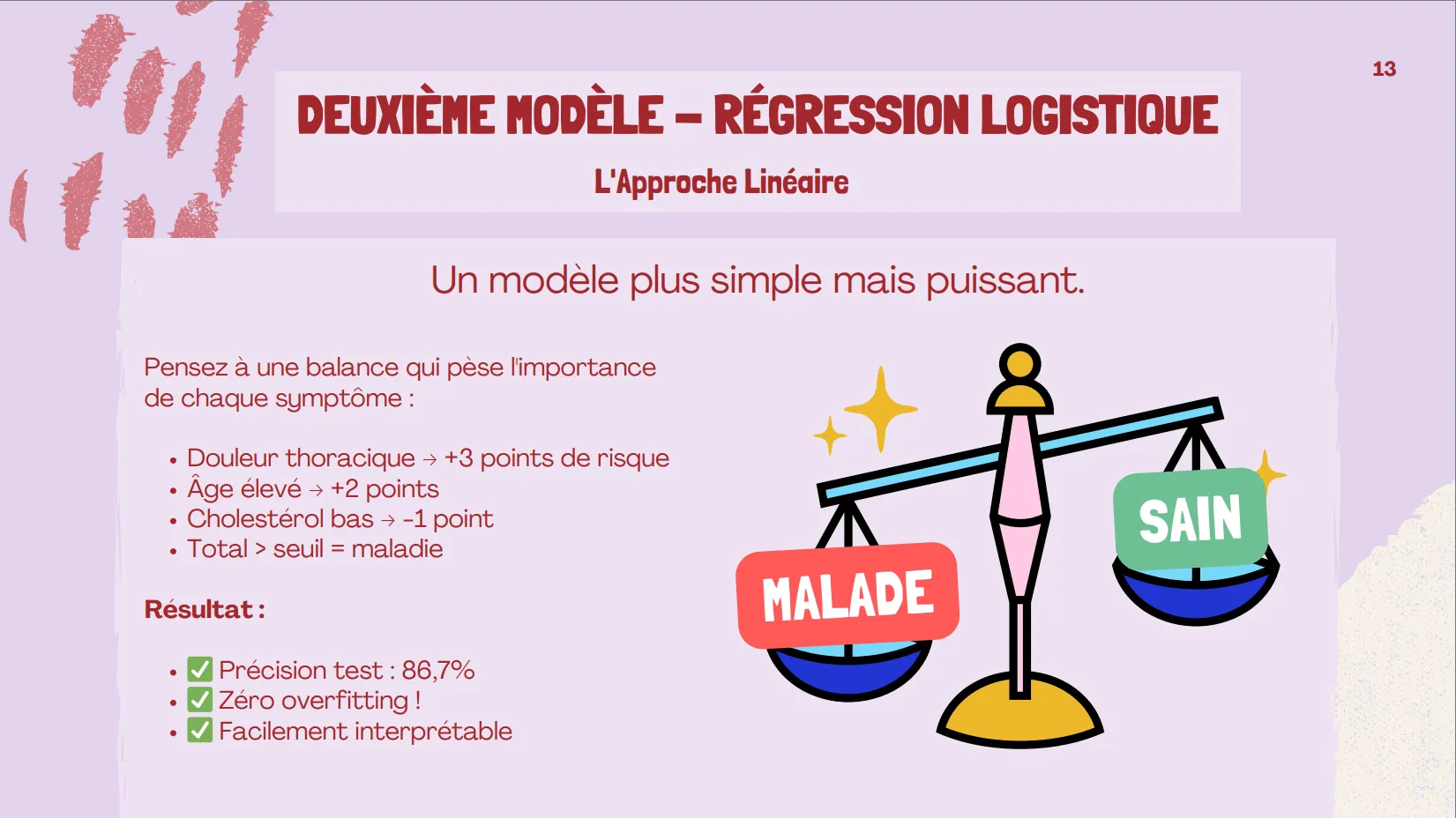
Modèle 2 – Régression logistique :
GridSearchCV avec régularisation L2 (C : 0,01)
Résultat : précision de 86,7 %, AUC de 0,951, aucun overfitting
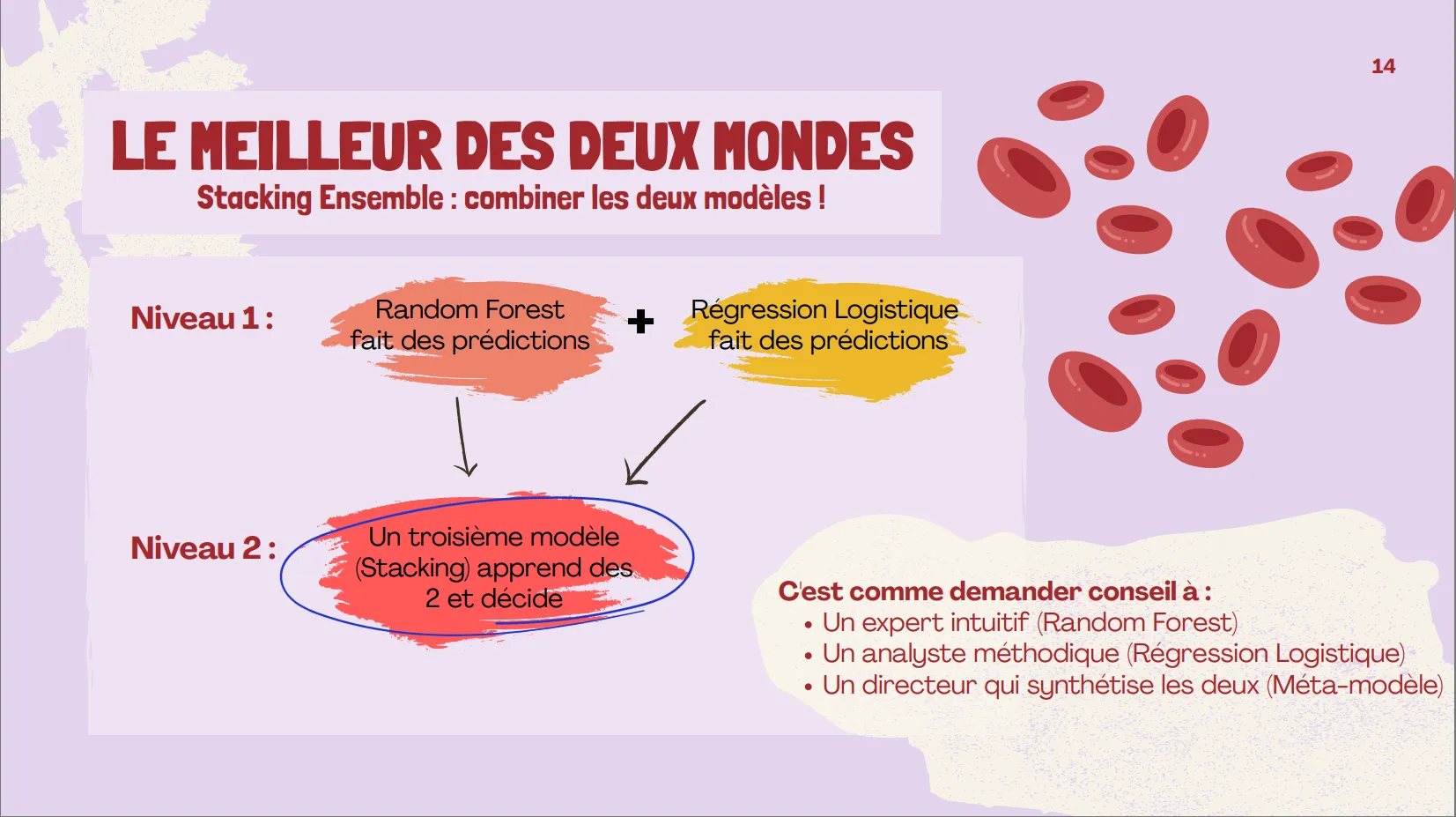
Modèle 3 – Stacking Ensemble :
Modèles de base : Random Forest optimisée + régression logistique
Métamodèle : régression logistique avec CV à 5-fold
Résultat : précision de 83,3 %, AUC de 0,953 (meilleure discrimination)
3. Analyse de l'importance des features :
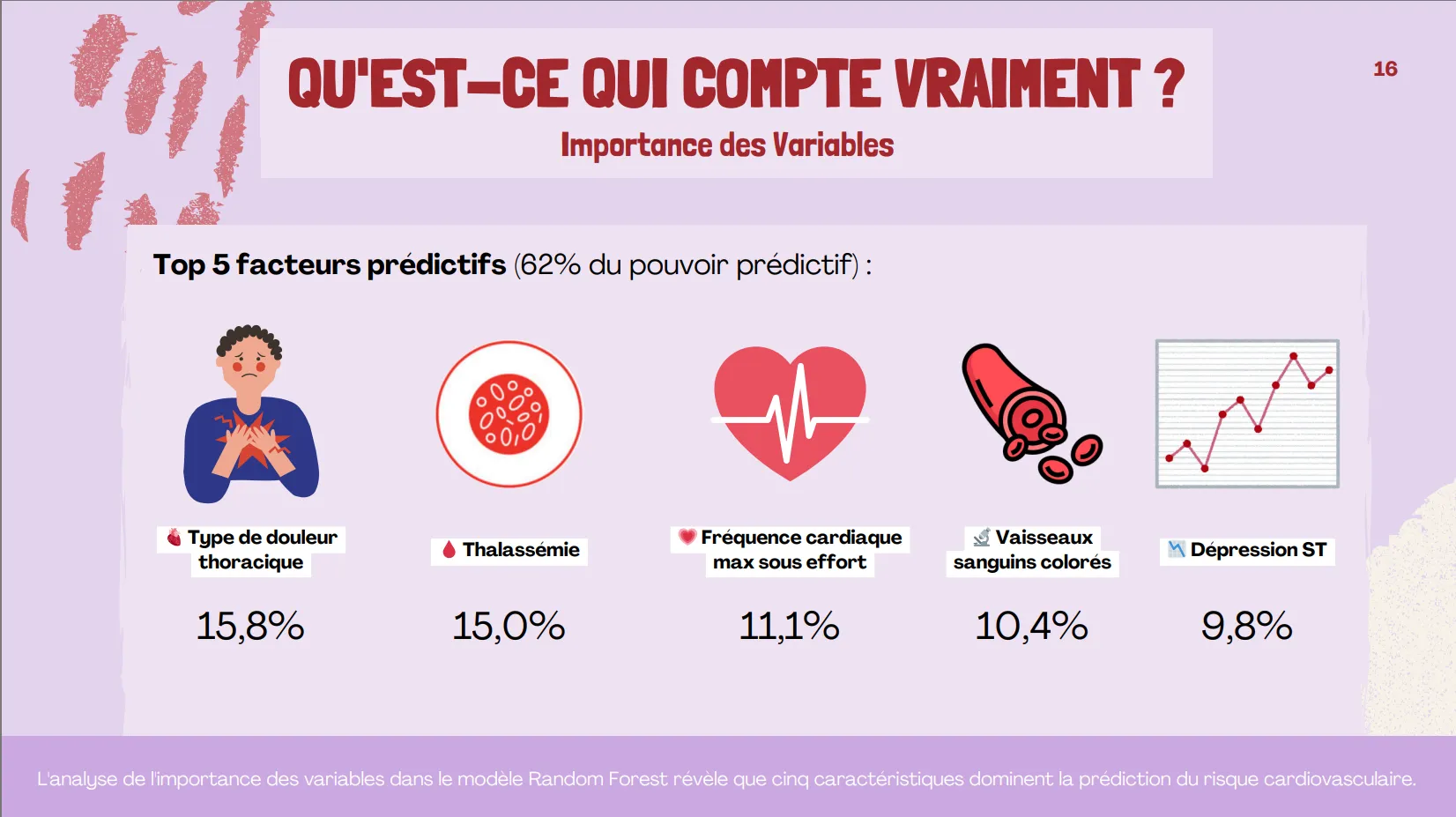
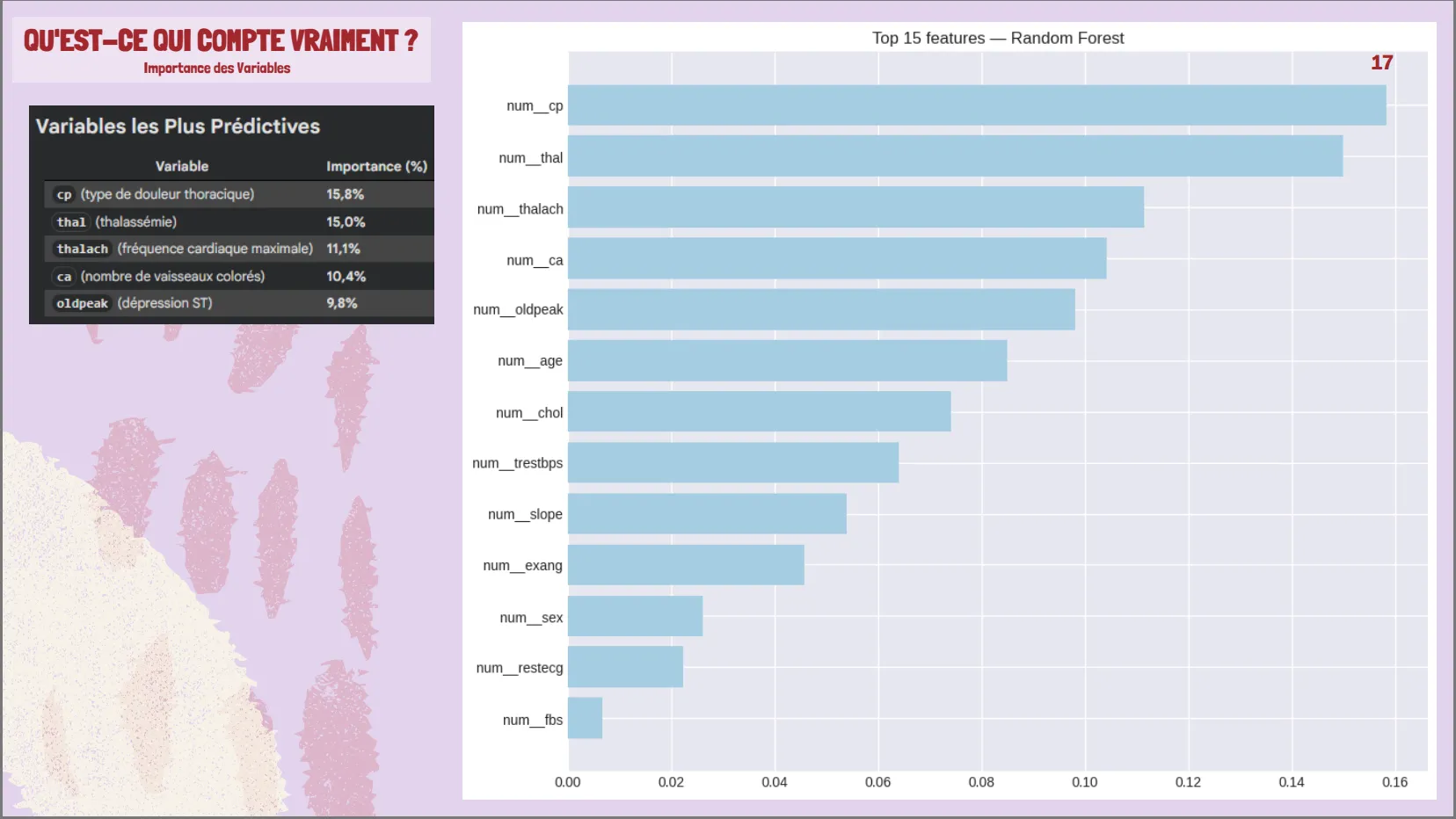
Les 5 principales variables prédictives (importance totale de 62 %) : type de douleur thoracique (15,8 %), thalassémie (15,0 %), fréquence cardiaque maximale (11,1 %), vaisseaux colorés (10,4 %), dépression du segment ST (9,8 %)
Conclusion surprenante : le cholestérol et la glycémie à jeun présentaient une faible corrélation avec la variable cible.
4. Développement du tableau de bord :
Génération de 133 056 scénarios What-if grâce à des combinaisons systématiques de paramètres
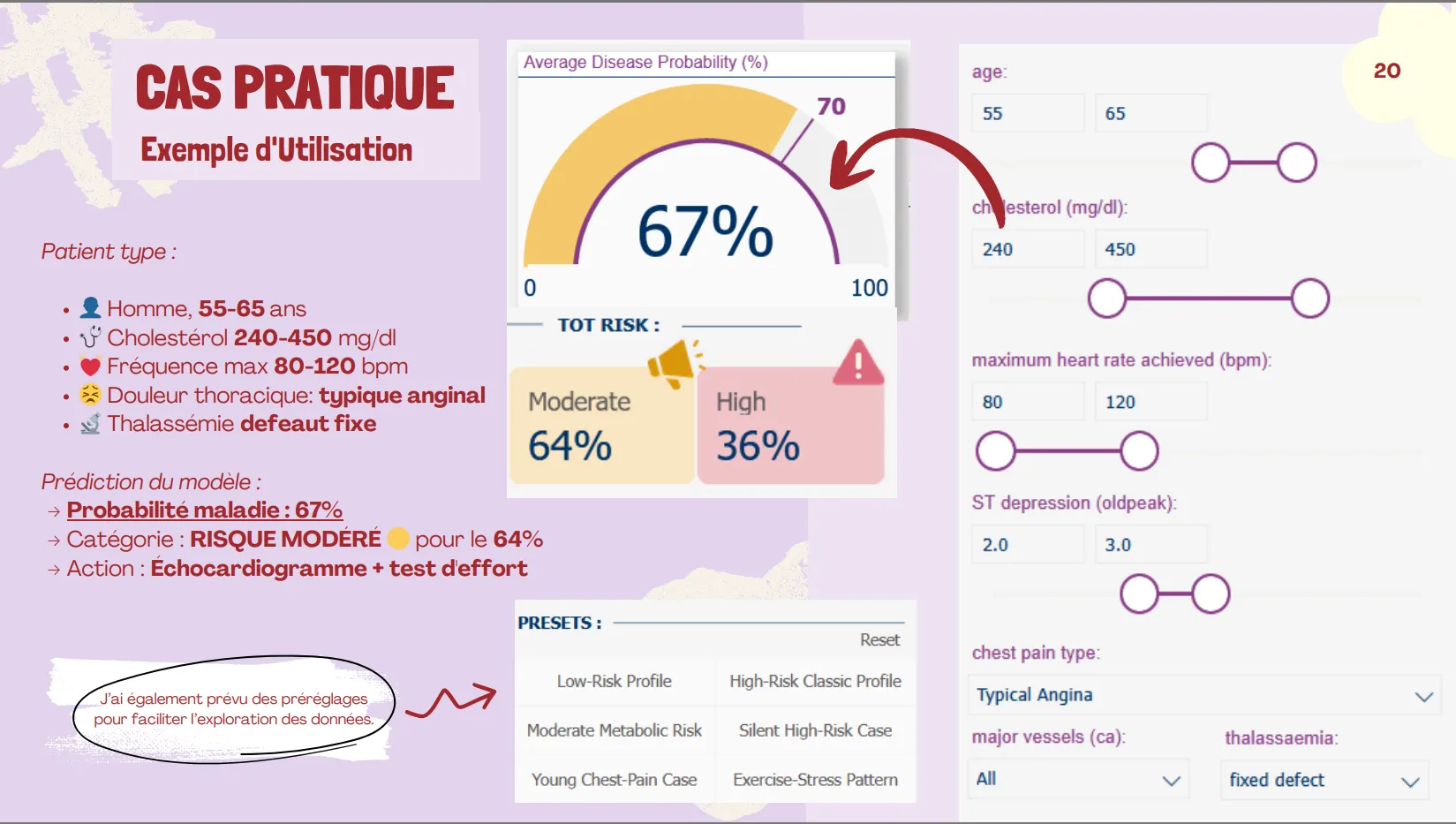
Catégorisation des risques : Faible (<30 %), Modéré (30-70 %), Élevé (≥70 %)
Tableau de bord Power BI interactif avec filtres pour l'âge, le cholestérol, la fréquence cardiaque, le type de douleur thoracique, la thalassémie, le sous-dépression du segment ST, les vaisseaux colorés
Exporté sous le nom heart_disease_dashboard_stacking.csv
Insights
Modèle 1: Random Forest (Optimisé)
- Test Accuracy: 85.0%
- Test AUC-ROC: 0.946
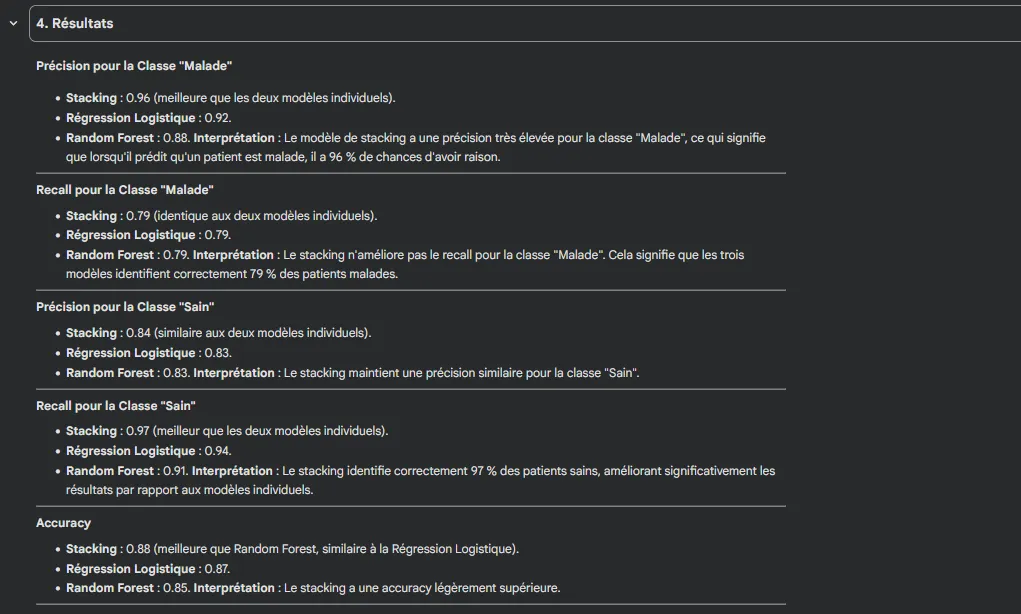
- Precision (Maladie): 0.88
- Recall (Maladie): 0.79
- F1-Score: 0.83
- Réduction de l'écart d'overfitting : de 11,2 % à 6,1 % (amélioration de 45 %)
Modèle 2 : Régression logistique
- Test Accuracy: 86.7%
- Test AUC-ROC: 0.951
- Precision (Maladie): 0.92
- Recall (Maladie): 0.79
- F1-Score: 0.85
- Généralisation : excellente (écart négatif = test > training)
Modèle 3 : Stacking Ensemble (Selectionné)
- Test Accuracy: 83.3%
- Test AUC-ROC: 0.953 ✨ (le plus élevé)
- Cross-validation AUC: 0.903
- Precision (Maladie): 0.88
- Recall (Maladie): 0.75
- F1-Score: 0.81
- Overfitting: Négligeable
Principales conclusions
✅ Stacking a permis d'obtenir la meilleure discrimination (AUC = 0,953).
✅ Random Forest présentait la sensibilité la plus élevée (79 % de rappel = moins de cas manqués).
✅ La régression logistique présentait la plus grande précision (92 % = moins de fausses alertes).
✅ Tous les modèles ont dépassé 0,94 AUC (excellentes performances cliniques)
Importance des features (Top 5)
- Type de douleur thoracique (cp) : 15,8 %
- Thalassémie (thal) : 15,0 %
- Fréquence cardiaque maximale (thalach) : 11,1 %
- Vaisseaux colorés (ca) : 10,4 %
- Dépression ST (oldpeak) : 9,8 %
Contribution totale :62 % de pouvoir prédictif
Business Impact
Pour les cliniciens :
- Outil de dépistage rapide avec une précision de discrimination de 95 % facilitant les décisions de triage
- Priorisation fondée sur des preuves : identifie les patients qui ont besoin d'un bilan cardiologique immédiat par opposition à un suivi de routine.
- Prévisions explicables : l'importance des caractéristiques montre quels facteurs cliniques influencent l'évaluation des risques.
Pour les patients :
- Communication visuelle des risques : un tableau de bord interactif traduit des probabilités complexes en catégories claires : faible, modérée, élevée.
- Autonomisation : les patients peuvent voir comment des changements de mode de vie (réduction du cholestérol, amélioration de la condition physique) auraient un impact sur leur score de risque.
Pour le système de santé :
- Optimisation des ressources : concentre les tests diagnostiques coûteux (échocardiogrammes, angiographies) sur les patients à risque modéré/élevé.
- Économie préventive : le dépistage précoce réduit les interventions d'urgence et les hospitalisations coûteuses.
- Évolutivité : modélise instantanément des scénarios illimités pour la gestion de la santé publique.
Contribution scientifique :
- Démontré que les méthodes d'ensemble (Stacking) combinant des approches linéaires et non linéaires surpassent les modèles individuels.
- Confirmation que les variables diagnostiques (caractéristiques de la douleur thoracique, résultats des tests d'effort) sont plus informatives que les facteurs de risque isolés.
- Méthodologie reproductible fournie pour les petits ensembles de données médicales (n = 303) avec contrôle rigoureux de l'overfitting.
Limites reconnues :
- La petite taille de l'échantillon (303 patients) limite la généralisation.
- Biais géographique (4 hôpitaux seulement)
- Recall de 75 à 82 % : certains patients malades échappent encore au dépistage (faux négatifs)
- Nécessite une validation sur des cohortes de patients potentiels dans le monde réel.